Maxine overview
Maxine allows the creation, organization, manipulation and animation of the different elements that constitute the virtual scenario through a scene graph. The following elements can be represented in a scene graph:
• Images and texts. They can be shown and positioned as rectangles oriented in space. The tool allows the loading of the main graphic formats (bmp, gif, jpeg, pic, png, rgb, tga, tiff) and can manage alpha-channel when it is supported by the graphic format.
• Simple geometric primitives but also complex geometric models. Maxine can import the most popular formats (3DS, flt, lwo, md2, obj, osg, DirectX), so that complex virtual scenarios with high level of detail can be created.
• Simple lights.
• 3D and ambient sound.
• Animated characters. They use the format of the Cal3D animation library and can be generated with common commercial 3D modelling and animation toolkit. Different types of animations are available including secondary animation to increase the characters’ expressivity and realism.
• Animated Actors. They are a specialization of the previous ones and they are provided with voice synthesis and facial animation with lip-synch, following the VHML standard and the MPEG4 specification for facial animation.
• Synthetic voices. Text can be provided by the user or by file, and can be associated to an actor (or not). Several tags are used to configure and control some audio characteristics like voice selection, volume control, speech speed, insertion of pauses, tone, word emphasis, pronunciation specification, etc.
The engine can manage several auxiliary elements like cameras, group of elements, animators (for animating group of elements),… and can also include animations coming from motion capture systems.
The Maxine Modules: Managing the agents
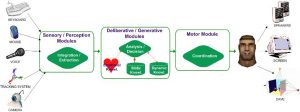
The “Sensory Module” integrates all the information coming from inputs to the system. Special attention was paid to creating multimodal user interaction, via mouse, via text thanks to the console and the scripting language, via voice by means of simple orders or questions caught by a microphone and via webcam to obtain from user’s face information such as his/her emotional state. The “Perception Module” is responsible for extracting the relevant information present in the input information. The interpretation of the voice input and the user’s image is of particular interest. The voice recognition engine has been constructed on the basis of Loquendo ASR (Audio Speech Recognition) software. The objective of the image input is to detect the user’s emotional state. The “Deliberative Module” analyses the information from the Perception Module and is responsible for decision making. It is basically in charge of generating the answers to the user’s questions and for classifying the user’s emotions. In both cases, a static (fixed answers) and dynamic (precedent questions) knowledge base is required. The answer engine system is based on the chatbot technology of the Artificial Intelligence Foundation using CyN under GNU GPL licence. In our case, the system has been designed for short and specific conversations. The knowledge base of the virtual character is stored in AIML files (Artificial Intelligence Markup Language).
The “Generative Module” is responsible for establishing the avatar’s reactions to the system inputs. It receives information from the Perception Module (in the case of purely reactive actions) or from the Deliberative Module (when decisions are considered). For the time being, the behaviour is based on an action/reaction schema and is managed by a hierarchical state machine. This module plays around with the avatar’s body movements, facial expressions and voice. In all three cases, the answer is modified in accordance with avatar’s emotional state.
The “Motor Module” manages and supervises the carrying out of low-level actions involving, in particular, the execution, synchronization and blending of the avatar’s body and face animations, lip-sync and the synchronization of execution sequences, etc. The skeletal animation technique is used for both facial and body animation and the nomenclature followed is that of the VHML standard.
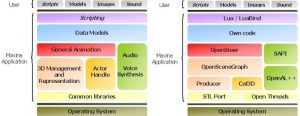
The Maxine architecture: Open source libraries